Cooperative Computing Tools (CCTools)
During the summer of 2022, I had the fantastic opportunity to work at the Cooperative Computing Lab (CCL) under the guidance of Prof. Douglas Thain. I was involved in developing the Cooperative Computing Tools (cctools), an open-source toolkit for HPC entirely built in C.
This summer research stint was packed with collaboration and hands-on experience, especially with Git and GitHub. Our Senior Software Engineer initially helped us tidy up our Git history, setting a solid foundation for the work ahead. I also dove into the book Pro Git to deepen my understanding. By summer’s end, I was the go-to person for resolving Git issues among my peers!
Visit here to view a all my pull requests. The two major contributions I made are described in the following sections.
Transaction Log Visualization
I developed a Python tool to designed to visualize the transaction logs generated by work_queue in order to identify performance bottlenecks in the distributed computing system. Recognizing that matplotlib alone was inadequate for this task, I conducted research on alternatives and decided to utilize the Bokeh library.
To know more about this tool, see:
- The blog post written by Dr. Thain.
- The Pull Request #2872
- The source code of this tool, note that it has likely been enhanced since I initially developed it.
The following are examples of generated visualization.
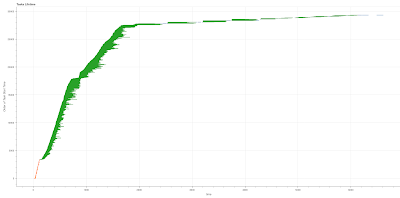

It’s incredibly rewarding to see my work make a lasting impact! After my first stint at CCL, I was thrilled to learn that:
- This visualizer is actively used in research, the graphs it created were featured in the research papers.
- CCL is in the process of developing a new online dashboard, which continues to use Bokeh for interactive visualizations. It’s great to see that my choice of technology has been well-received and adopted for ongoing projects!
“Draining” a Work Queue Factory
A feature request was raised on Jan 15, 2016:
I’m not sure if this is even a sensible request, but it would be really nice if you could “drain” a work queue factory–in other words, tell a factory that it should reduce the number of connected workers, but only by removing workers after they complete their current tasks.
6 years after this feature request is proposed, I claimed this issue and implemented a mechanism to reduce the number of distributed workers without compromising task progress.
For more details see the Pull Request #2912. I quote from it the way I design this system:
- Work Queue Factory includes
FACTORY_NAMEto indicate where the workers come from.
- A command line argument for work_queue_factory to specify factory_name.
- A command line argument
--from-factory <factory_name>forwork_queue_worker.- In read_config_file,
work_queue_factorylaunches the workers with--from-factory=..argument.- Factory reports this
workers_maxto the catalog server.- Manager reads the info and take actions.
- Manager reads
workers_maxfrom the catalog server.- Manager maintains a dictionary of factory structs.
- Manager sends shutdown signal to excessive workers in the factory that are not running any tasks.
- Do not dispatch tasks to workers until currently connected workers is less then
workers_max.- Whenever the last task on the worker is returned, shut down that worker.